What is Data Fabric? A Modern Data Management Framework
Data Fabric provides a unified data architecture that connects disparate systems, enabling seamless integration, governance, and insights. Learn how this next-generation data management framework breaks silos, improves agility, and supports scalable analytics in today’s complex, distributed environments.

What is Data Fabric?
Data Fabric is a modern data management architecture designed to address the challenges of data integration, accessibility, and governance in today’s distributed, hybrid, and multi-cloud environments. It creates a unified layer that connects structured and unstructured data across systems, applications, and locations, allowing organizations to unlock actionable insights and enhance innovation.
At its core, Data Fabric emphasizes data agility, scalability, and trust. It leverages technologies such as data virtualization, metadata management, and AI-driven governance to provide a holistic view of enterprise data assets. By eliminating data silos, Data Fabric enables faster decision-making, improves data quality, and accelerates digital transformation initiatives.
One of its biggest strengths is adaptability. As organizations evolve, Data Fabric seamlessly incorporates new data sources and analytical tools without disrupting existing workflows. This flexibility makes it a cornerstone of modern enterprise data strategy bridging on-premise, cloud, and edge environments for consistent, governed, and scalable data access.
Data Fabric: A Conceptual Model
Rather than a specific tool or product, Data Fabric is an architectural concept that defines how organizations should connect, manage, and utilize data across heterogeneous systems. Its purpose is to create a cohesive, integrated data environment where data sharing, collaboration, and discovery occur effortlessly.
Data Fabric integrates multiple components:
- Data integration and virtualization tools
- Metadata and master data management systems
- Automated data governance frameworks
These components collectively enable a unified and intelligent data ecosystem.
Within this architecture, Relational Data Warehouses (RDWs), Data Lakes, and Modern Data Warehouses (MDWs) coexist and interoperate:
- Relational Data Warehouses (RDWs): Handle structured data for business intelligence and reporting, supporting SQL-based queries and standardized schemas. Within a Data Fabric, RDWs serve as reliable sources of truth for structured datasets.
- Data Lakes: Store unstructured, semi-structured, and raw data at scale, supporting big data analytics, AI, and machine learning workloads. Data Fabric integrates Data Lakes to enable flexible exploration and data science experimentation.
- Modern Data Warehouses (MDWs): Combine the scalability of Data Lakes with the governance of RDWs, supporting real-time analytics, cloud-native operations, and multi-format data integration.
By combining these components, Data Fabric creates an end-to-end architecture that supports data discovery, quality management, and governance at scale—empowering organizations to deliver trusted, analytics-ready data to every user.
An Analogy to Understand Data Fabric
Imagine Data Fabric as an internal “Google for enterprise data.” Just as Google Search Engine (GSE) indexes and categorizes web pages for instant retrieval, Data Fabric catalogs and organizes metadata across disparate enterprise systems.

Metadata Indexing
- Google Search Engine: Indexes metadata like titles, descriptions, and keywords to rank and retrieve web pages.
- Data Fabric: Collects metadata from multiple data sources—such as lineage, data quality scores, and usage policies to build an intelligent enterprise data catalog.
Data Discovery and Categorization
- Google Search Engine: Uses metadata to deliver relevant and ranked search results.
- Data Fabric: Enables users to search, filter, and discover data assets across systems using metadata attributes, enhancing data democratization and self-service analytics.
Enhanced Data Accessibility
- Google Search Engine: Simplifies access to relevant information through intuitive search experiences.
- Data Fabric: Provides a unified interface for accessing all enterprise data, ensuring users can find trusted data quickly while maintaining compliance and security.
In short, Data Fabric functions as an intelligent data discovery and access layer, transforming how organizations index, manage, and utilize their data—similar to how Google revolutionized the web.
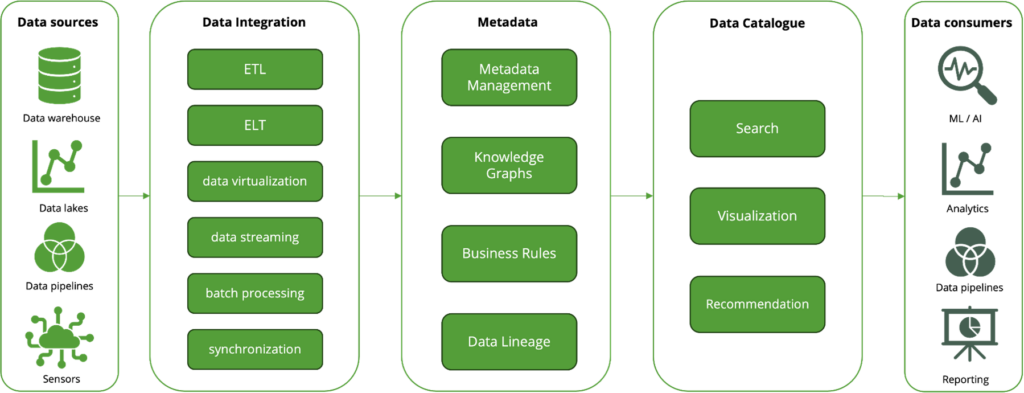
Layers in a Data Fabric Architecture
A Data Fabric typically consists of five key layers, each contributing to a unified, intelligent, and governed data ecosystem.
Conclusion
In today’s multi-cloud and hybrid data ecosystems, Data Fabric has become a cornerstone of modern data strategy. By combining automation, AI-driven metadata, and strong governance, it creates a scalable, agile, and intelligent data infrastructure that supports analytics, innovation, and digital transformation.
As Gartner and Forrester highlight, organizations adopting Data Fabric experience improved data accessibility, faster analytics delivery, and reduced operational complexity, giving them a competitive advantage in the data-driven economy.
Knowledge - Certification - Community

